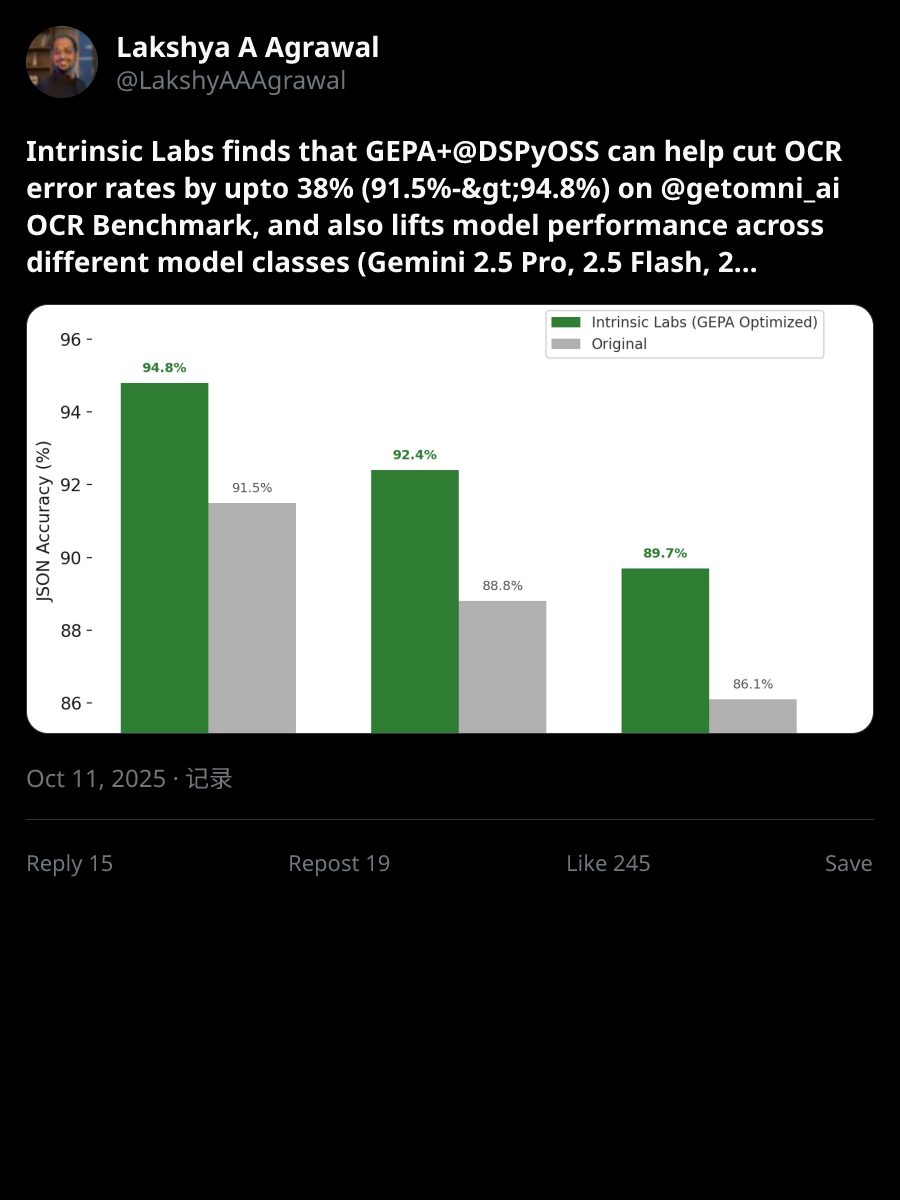
GEPA is a SUPER exciting advancement for DSPy and a new generation of optimization algorithms re-imagined with LLMs! Starting with the title of the paper, the authors find that Reflective Prompt Evolution can outperform Reinforcement Learning!! Using LLMs to write and refine prompts (for another LLM to complete a task) is outperforming (!!) highly targeted gradient descent updates using cutting-edge RL algorithms such as GRPO!! GEPA makes three key innovations in how exactly we use LLMs to propose prompts for LLMs — (1) Pareto-Optimal Candidate Selection, (2) Reflective Prompt Mutation, and (3) System-Aware Merging for optimizing Compound AI Systems. The authors further present how GEPA can be used for training at test-time, one of the most exciting directions AI is evolving in!